Datenwachstum, Datenexplosion - das Wissen der Menschheit entwickelt sich rasend, das Volumen der gespeicherten Daten noch schneller. Das Problem: Die passenden Daten in dem ungeheuren Digital-Konvolut wieder zu finden. IBM sieht seinen Watson gerüstet, sich der Daten-Herausforderung zu stellen. Erstes Einsatzgebiet: die Naturwissenschaften.
"Wissen nennen wir den kleinen Teil der Unwissenheit, den wir geordnet haben", spottete schon Ambrose Bierce, der in keiner Zitatensammlung fehlen darf, im 19. Jahrhundert. Während seines Lebens (1842-1914), wird behauptet, habe sich das Wissen der Menschheit etwa verdoppelt. Heutzutage wird allerorten von der Datenexplosion gesprochen. Angesichts Schwindel erregender Zahlen ist der Begriff Daten-Supernova wohl angemessener.
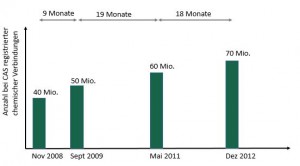
1968 seien 1 Mio. chemische Stoffe bekannt gewesen. Heute schlüpfen die chemischen Entdeckungen wie die Pilze aus dem Boden: Pro Minute sei ein neuer Stoff zu feiern. Die genaue Situation ist wegen der Dynamik unklar. Es kursieren die unterschiedlichsten Zahlen. Einige haben schon ein paar Jahre auf dem Buckel. Am verlässlichsten sind wohl die Zahlen, die der Chemical Abstracts Services herausgibt, der führende chemische Verzeichnisdienst. Von exponentiellem Anstieg des Wissens wird immer wieder gesprochen. Das stimmt auf Basis der CAS-Zahlen zwar nicht – zumindest nicht in den letzten Jahren (s. Grafik). Allerdings sollte noch in diesem Jahr die 80-Millionen-Marke für registrierte chemische Verbindungen fallen. Das entspräche einer Verdopplung des Wissens in etwa sechs Jahren. Und um den Faden von oben aufzunehmen: das wären dann 12 bis 13 neue Verbindungen pro Minute.
Das stellt Forscher natürlich vor Probleme. Schon vor 20 Jahren war es angesichts kilometer-langer Bibliotheksregale und Hunderter mehr oder weniger seriöser Fachmagazine schwierig, den Überblick zu behalten. Da erweist sich der Trend zur Digitalisierung als Segen. Und als Fluch. Die Digitalisierung ermöglicht zum einen den Einsatz elektronischer Suchhelfer, zum anderen aber leistet sie auch dem großzügigen Umgang mit Daten Vorschub. Und dem damit verbundenen Datenwachstum: Der elektronische Datenbestand verdoppelt sich alle zwei Jahre. 2020 wird die Menge an erstellten, vervielfältigten und konsumierten Daten bei 40 Zettabyte* liegen. Was das für den Internetverkehr bedeutet, haben wir bereits in unserer 60-Sekunden-Grafik aufgearbeitet.
Dass angesichts solcher Entwicklungen Cloud Computing und Big Data auch für Wissenschaftler immer relevanter werden, kann kaum mehr ernsthaft bezweifelt werden. Doch zu der Bewältigung und Filtration der schieren Mengen von Informationen kommt noch ein entscheidendes Moment hinzu. Das Menschliche. So sehr sich Google über immer menschlicher werdende Suchen freuen mag (Spracheingabe, Auto-Vervollständigung, nutzer-orientierte Suchergebnisse) – der Suchende ist noch längst nicht immer auch ein Findender. Aber das verspricht der Terminus Google-"Suche" ja auch gar nicht ;).
Es liegt auch an der Verständigung zwischen Mensch und Maschine: Wie kann man Google einfach begreiflich machen, dass ein Chemiker, um ein schwaches Beispiel zu machen, wenn er nach Katalysatoren sucht, eben keine Automobiltreffer braucht? Er braucht einen Übersetzer, der die Bedürfnisse und Interessen des Suchenden versteht und in der Lage ist, mitzudenken, über den Tellerrand zu schauen, thematisch zu suchen und zu interpretieren. Der die Sprache des Suchenden "spricht".
So einen wie Watson. Drei Jahre ist es jetzt her, als IBMs Erfindung bei Jeopardy seine menschlichen Kontrahenten düpierte. Nun sieht Big Blue eine kommerzielle Nische für seinen Einsatz: Watson as a Service. Aus der Cloud. Mit seiner Fähigkeit zur Konversation kann er komplexe Suchanfragen bearbeiten. Eine Cloud-Infrastruktur verschafft ihm die notwendige Rechen- und Speicherkapazität automatisch. Mit Watson as a Service schlägt IBM wohl ein neues Kapitel in Sachen Big Data auf. Big-Data-Analysen werden einfacher für den Nutzer.
Und wenn man einen Ausblick wagt: Vielleicht erledigt sich das Aufsetzen komplexer Big-Data-Projekte, wenn sich Watson noch weiter entwickelt. Dann bekämen die Suchenden umfangreiche Auswertungen tatsächlich auf Knopfdruck. Ein einfaches Briefinggespräch mit Dr. Watson reicht. Visionär, aber auch ein bisschen erschreckend. Bedarf dafür ist allemal da, denn wie es der Prediger formuliert: "Des vielen Büchermachens ist kein Ende". Irgendwann werden die Zettabytes auch die Anzahl der Wassermoleküle übersteigen ...
Vielleicht wäre so ein Watson auch was für divia. Der könnte uns viel Markt-Analyse-Arbeit abnehmen. Leider hält sich IBM bei den Preisen noch bedeckt ...
* 1 Zettabyte = 1 000 000 000 000 000 000 000 Byte, das liegt leicht über der Menge aller Sandkörner auf den Stränden der Erde.
{kind=link}
{kind=link}
{kind=link}